
消息队列
为什么
主要作用:
- 异步:提高系统响应速度以及吞吐量
- 削峰填谷:稳定平滑系统流量
- 解耦:减少服务之间的影响,提高系统整体的稳定性以及扩展性
主要缺点
MQ 是基于事件驱动的。消息由生产者发送到MQ进行排队,然后按FIFO的顺序交由消息的消费者进行处理。其主要缺点:
- 系统可用性降低:外部依赖增加,稳定性变差,要考虑MQ的高可用
- 系统复杂度提高:消息链路追踪复杂,顺序也要保证
- 消息一致性问题
怎么用(生产环境关注公有云服务)
公有云产品
官网消息队列全景:https://www.aliyun.com/product/ons?spm=5176.23056729.J_3207526240.58.3dcc3f06fc3SNi
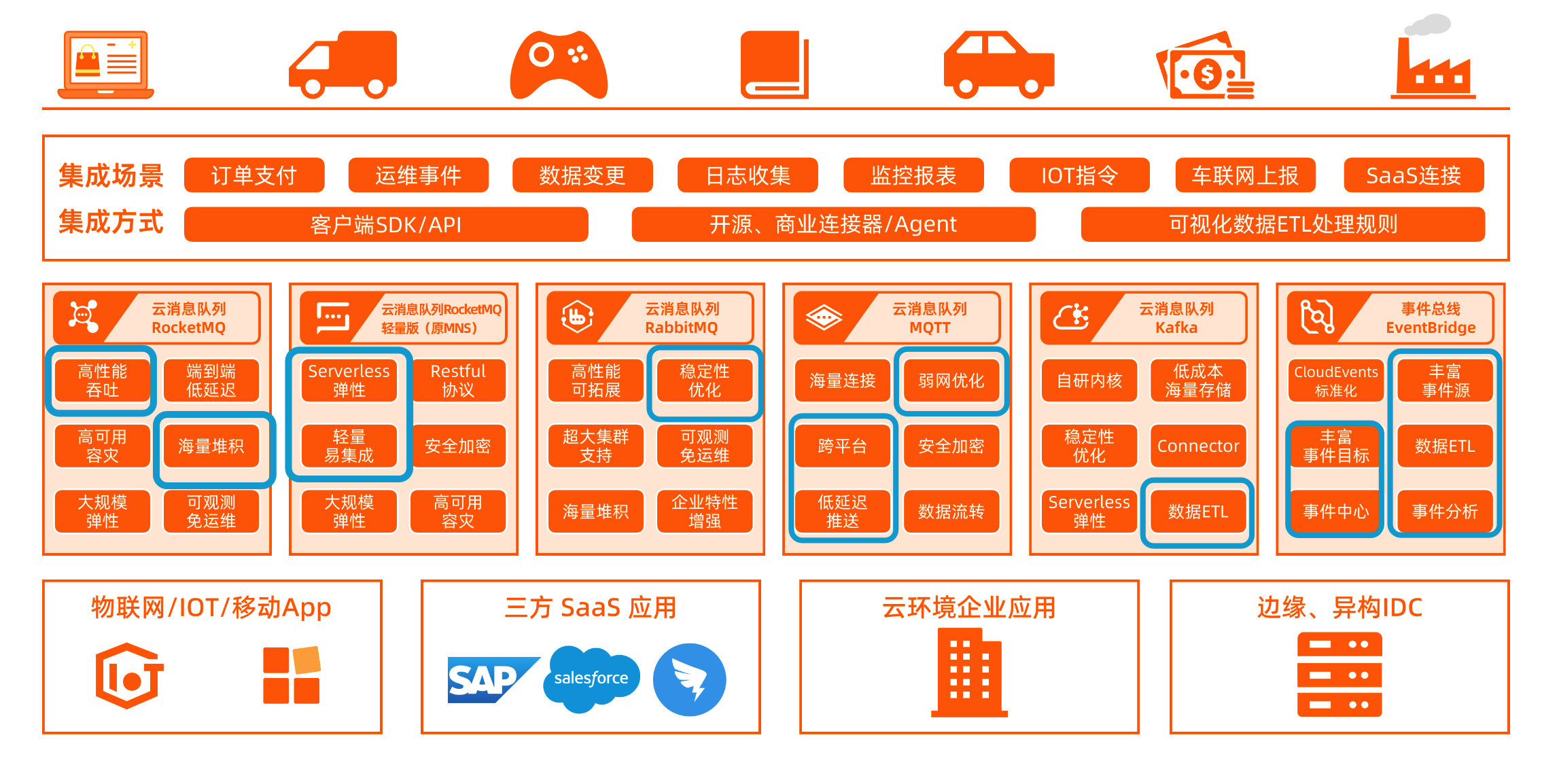
- MQTT 是给车联网使用, 适合消息比较小且多的跨端消息传输
- rabbit 主要是为了原有使用 rabbit 的项目快速迁移,以及增强了 rabbitMQ 的稳定性,降低了运维的成本
- kafka 主要用来给大数据日志分析使用,
- eventBridge 主要用来给 SaaS 平台提供事件总线的能力,实现不同系统之间的解耦以及数据的事件通知机制。如果平台和 EventBridge 有集成,例如钉钉有数据变动的时候可以直接通过EventBridge投递到数据库的变更中https://help.aliyun.com/document_detail/434630.html
- MNS:提供的功能其实也没有那么简陋,相比 rocketMQ 概念确实更少,但是确实没什么需要使用的场景。或许在一些函数计算需要简单使用MQ的场景有用武之地。
- RocketMQ 这个懂得都懂,做一些业务相关的应用服务,是提供最完善和稳定支持的MQ,所以一般的应用开发MQ场景,无脑使用 RocketMQ
事件总线 EventBridge
事件驱动无服务计算:“事件”可以是云产品的事件,也可以是自定义事件源,“无服务计算”可以是Function、API、K8s Service。
使用场景:
- 无服务计算,新 serverless 函数计算等技术快速接入事件处理的能力
- 异构系统之间想要实现事件的互相消费的时候
无服务器事件总线服务,最主要是支持不同架构(自建应用服务,阿里云服务,SaaS 应用服务,中心化服务)之间建立关系,也就是支持建立松耦合的事件驱动架构。
使用的时候一般是低代码的配置方式继承或被集成,连接云产品和自己的应用或者SaaS应用。在 Serverless 里面可以支持更多的函数快速接入使用
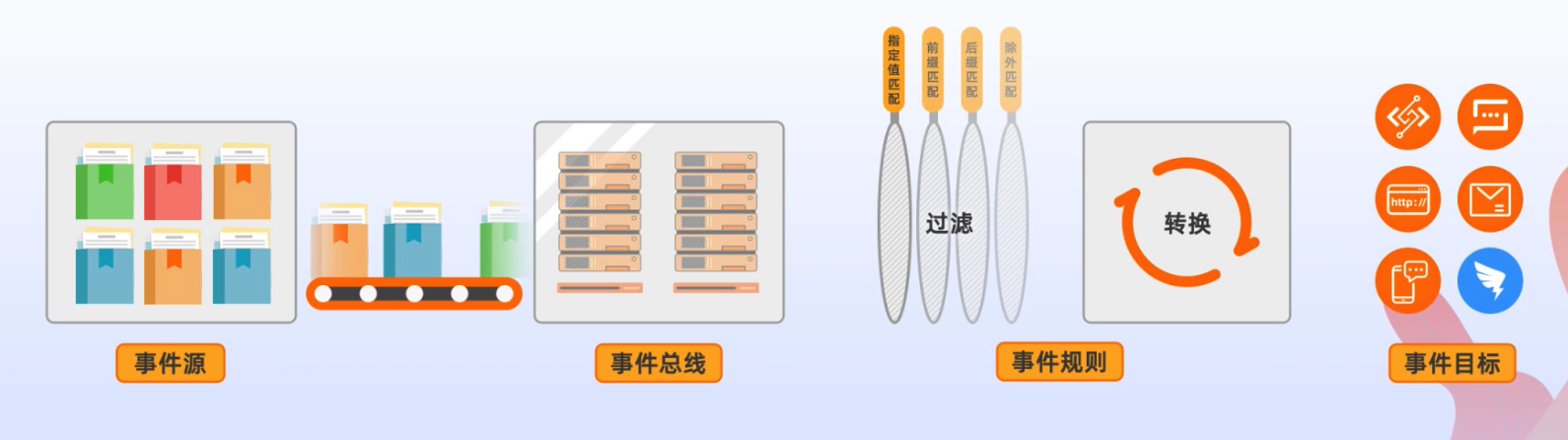
- 事件源:阿里云服务、SaaS 服务、自定义服务、自定义数据源
- 事件总线:云服务专用总线、自定义总线
- 事件规则:过滤器规则可以用来过滤符合要求的事件,转换器可以将CloudEvent转换为事件目标要求的数据格式
- 事件目标:钉钉、函数计算、消息服务、事件总线、消息队列、短信服务、邮箱服务、HTTPS。每个事件最多可以触发5个事件目标
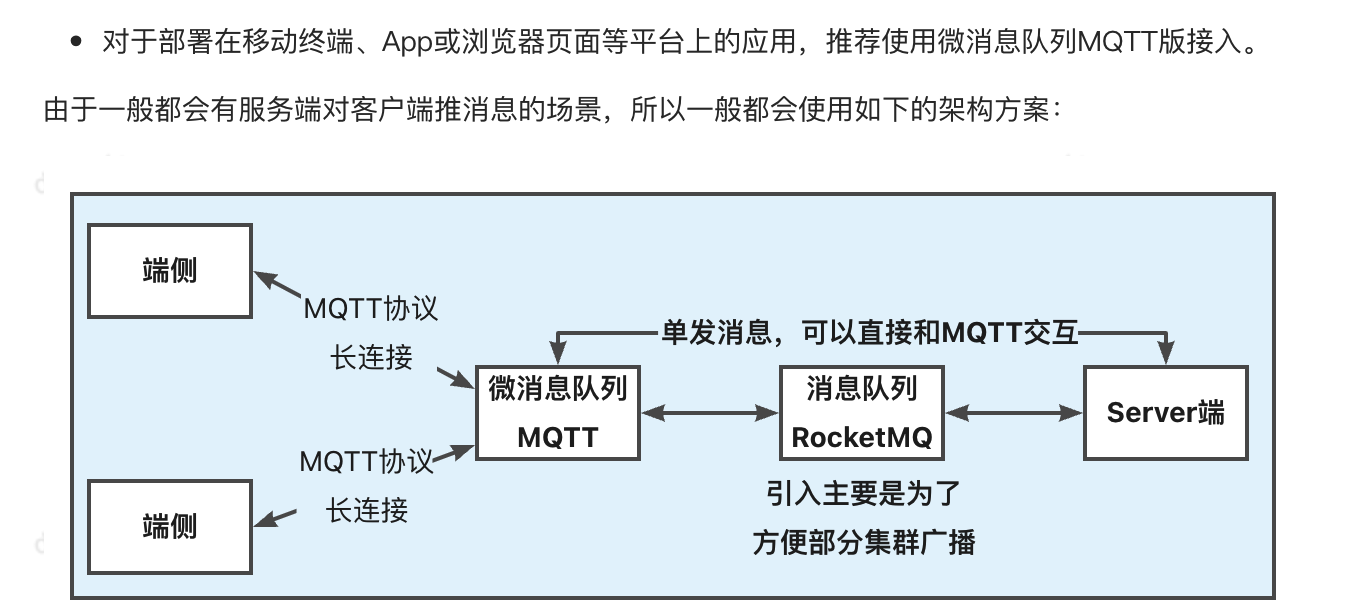
微消息队列MQTT
云产品 RocketMQ
基本的概念和开源的没有什么区别,只是一些高级特性上有一些优化,比如商业版是可以实现消息只有一次到达的。这里研究原理使用开源版。
实际生产环境最好使用商业版本,是因为:

ons 最开始是为了屏蔽具体的 MQ的类型,让用户引入依赖的时候不需要关注具体的MQ类型,而是只有一个 ons-client ,但是商业版 RocketMQ 最新版的依赖已经替换为具体的rocketmq-client-java依赖。
开源中间件
RabbitMQ
简单介绍
企业内部用的最经典的消息队列。但是在生产上是有一些稳定性的问题和分布式的问题需要关注的。
基本概念
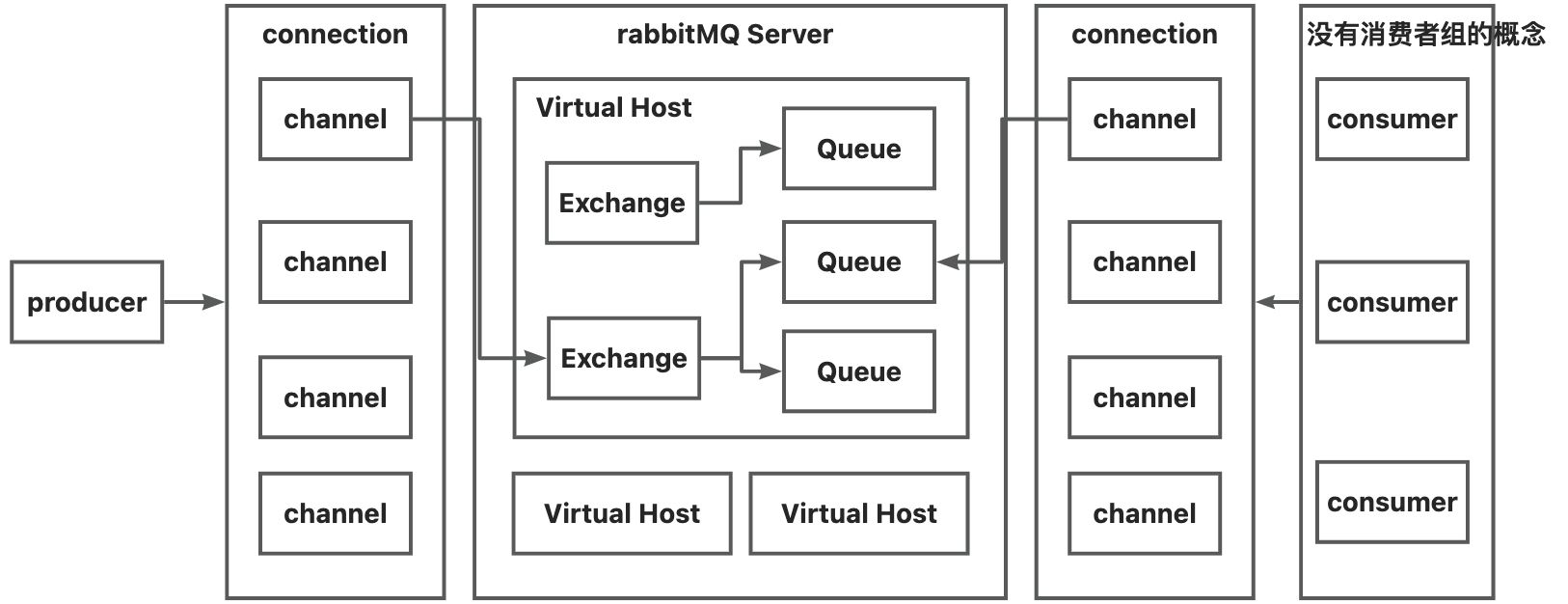
- virtual host 虚拟机:一个实际的物理实例上是可以创建多个虚拟机,这些虚拟机在外界看来就是一个个的服务实例。数据权限都是分开的。
- 集群模式:
- 普通集群模式:集群节点之间有相同元数据,但是消息只会在某一节点。会在请求过来的时候,如果当前节点没有数据,临时从有数据的机器拉取数据。有单点故障的问题(可用性以及重复消费)。
- 镜像模式:官方推荐,普通集群模式的增强,消息会主动在集群节点之间同步,每个节点都存在全量消息(最好不要创建太多的队列,否则会降低集群性能)。使用的时候创建虚拟主机,然后添加对应的镜像策略。
- 队列,创建时候的注意事项:
- 虚拟机的选择:如果要高可用要选择创建了镜像策略的虚拟主机。
- 队列的类型:
- 经典队列Classic:单机较高可靠性,可以设置是否持久化(Durable和Transient)以及自动删除队列。
- 支持独占队列(只能由声明该队列的Connection连接来进行使用,包括队列创建、删除、收发消息等,并且独占队列会在声明该队列的Connection断开后自动删除。)
- 仲裁队列Quorum(从3.8.0版本):分布式下更可靠。基于raft,持久化和多备份队列,需要多个节点过半统一才会写到队列。
- 支持毒消息(一直不被消费)的处理,超过设置的阈值就会删除或者放到配置的死信队列。
- 处理比较慢,可能会消息积压,不支持独占和临时队列。适合延时要求低,但不丢失的场景。
- 流式队列Stream(自3.9.0版本):持久化到磁盘并且具备分布式备份的,更适合于消费者多,读消息非常频繁的场景。消息顺序写,调整每个消费者消费进度offset实现多次分发。
- 一个队列就可以给多个消费者消费同样的消息,不用创建多个队列
- 允许读取已经消费过的消息,重置 offset
- 适合存储大量数据,适合高性能吞吐。
- 经典队列Classic:单机较高可靠性,可以设置是否持久化(Durable和Transient)以及自动删除队列。
- 消息的类型:会持久化到硬盘 Durable、不持久化 Transient
- 是否自动删除:至少一个已经连接,并且所有 consumer 都不用之后队列就会被删除。
- AMQP:是一个二进制协议,提供统一消息服务的应用层标准高级消息队列协议,是应用层协议的一个开放标准,为面向消息的中间件设计。特点:多信道、协商式,异步,安全,扩平台,中立,高效。RabbitMQ是AMQP协议的Erlang的实现。
- **Connection 连接与 Channel 信道:**一旦客户端与Server建立了 Connection(TCP连接,四元组只会有一个连接) 之后,就会分配一个 AMQP 的信道 Channel,进行实际数据的交互,为了减少性能开销,一个Connection 中会建立多个Channel,便于多线程连接,这些连接复用一个 Connection 的 TCP 通道。
- 交换机Exchange:主要起到路由的作用,消息从 channel 进来之后,通过交换机路由到不同的队列。交换机常见类型有:direct、fanout、headers、topic
简单使用
- 安装的时候需要先按照对应的 erlang 环境,再安装server
- 使用方式:原生API、SpringBoot、SpringCloudStream 三种模式
- 原生API的基本编程模型:具体代码可以参考:https://www.cnblogs.com/nongzihong/p/11927915.html
- 创建连接、获取Channel
- 声明队列:声明的队列,如果服务端没有,那么会自动创建。但是如果服务端有了这个队列,那么声明的队列属性必须和服务端的队列属性一致才行。
- 发送消息:设置传输的规则
- 消费消息:
- 被动消费模式:建立一个线程等待 server 推送消息,
- 主动消费模式:主动获取指定的 message 进行消费
- autoAck 决定是不是自动确认消费。
- 关闭连接释放资源
- 消息场景:
- **hello world:一个队列,一个消费者,**不需要交换机,直接指定queue来发送和消费
- work queues 工作序列:一个队列,多个消费者,依旧没有交换机,负载均衡决定谁消费队列。
- 关于自动确认:Consumer端的autoAck字段设置的是false,消费后不会自动反馈服务器已消费了message,处理完再调用channel.basicAck通知服务器已经消费了该message。没有ack的message会被服务器重新进行投递。
- 关于负载均衡策略:可以是轮询,也可以先询问consumer的处理能力来决定是否调用。但是都可能导致server的消息积压
- direct,fanout,topic等这些Exchange,都是以 routingkey为关键字来进行消息路由到不同的queue的,但是这些Exchange有一个普遍的局限就是 都是只支持一个字符串的形式
- pub/sub 订阅发布机制:type为 fanout 的exchange。一个交换机多个队列,往所有的队列上发消息。注意这里的队列是逻辑上的,是按照名字维度来的,不同实例的消费者消费的队列名字一样就只有一台机器会处理。这些消费同名队列的消费者可以理解为消费者组。
- **routing 基于key内容的精确匹配路由:**type为 direct 的exchange。一个交换机多个队列,交换机将不同路由精确匹配key的消息发到不同的queue。
- topics 基于主题内容的模糊匹配路由:type为 topic 的exchange。这个是模糊匹配,词之间用
.隔开,*代表一个具体的单词。#代表0个或多个单词。
- headers 基于header的路由:Headers 类型的 Exchange 就是一种忽略 routingKey 的路由方式。他通过 Headers 来进行消息路由。发送者可以在发送的时候定义一些键值对,接受者也可以在绑定时定义自己的键值对。当键值对匹配时,对应的消费者就能接收到消息。
- 匹配的方式有两种,一种是all,表示需要所有的键值对都满足才行。另一种是any,表示只要满足其中一个键值就可以了。而这个值,可以是List、Boolean等多个类型。
- debug - info - warning - error四个级别的日志分开收集,收集时,每个队列对应一个日志级别,收集对应日志级别和以上的所有日志,就可以使用这个
- **rpc 远程调用:**不常用
- **Publisher Confirms 可靠消息发送机制:**新消息模型(阿里云MQTT微消息队列云端的SDK就是用的这个包装的),发送者消息确认,保证消息发给server是可靠的,前面都是保证consumer消费是可靠的。开启这个模式需要执行:
channel.confirmSelect();- 发布单条消息
channel.waitForConfirmsOrDie(5_000),同步阻塞channel,等待确认期间,不能再继续发送消息,明显降低集群的发送速度。 - 异步确认消息
channel.addConfirmListener(ConfirmCallback var1, ConfirmCallback var2);Producer在channel中注册监听器来对消息进行确认。- sequenceNumer:唯一的序列号,代表唯一的消息。在 RabbitMQ中,他的消息体只是一个二进制数组,并不像RocketMQ一样有一个封装的对象,所以默认消息是没有序列号的。而RabbitMQ提供了一个方法int sequenceNumber = channel.getNextPublishSeqNo());来生成一个全局递增的序列号。然后应用程序需要自己来将这个序列号与消息对应起来。
- multiple:这个是一个Boolean型的参数。如果是true,就表示这一次只确认了 当前一条消息。如果是false,就表示RabbitMQ这一次确认了一批消息,在 sequenceNumber之前的所有消息都已经确认完成了。
- 发布单条消息
RocketMQ
简单介绍
阿里2016开源后捐赠给Apache,在阿里云上有一个购买即可用的商业版本,商业版本集成了更深层次的功能及运维定制。
阿里最开始使用ActiveMQ,消息逐渐多之后,IO瓶颈。使用 kafka 但是 topic 多的时候就会 partition 也多,IO不行。自研的中间件叫 MetaQ,开源出来叫 RocketMQ。RocketMQ 将所有的消息使用顺序写的方式都追加到 commitLog 文件,每一个分片文件 consumerQueue 只维护索引信息,所以即使 topic 很多的时候也不会有IO问题。
基本概念
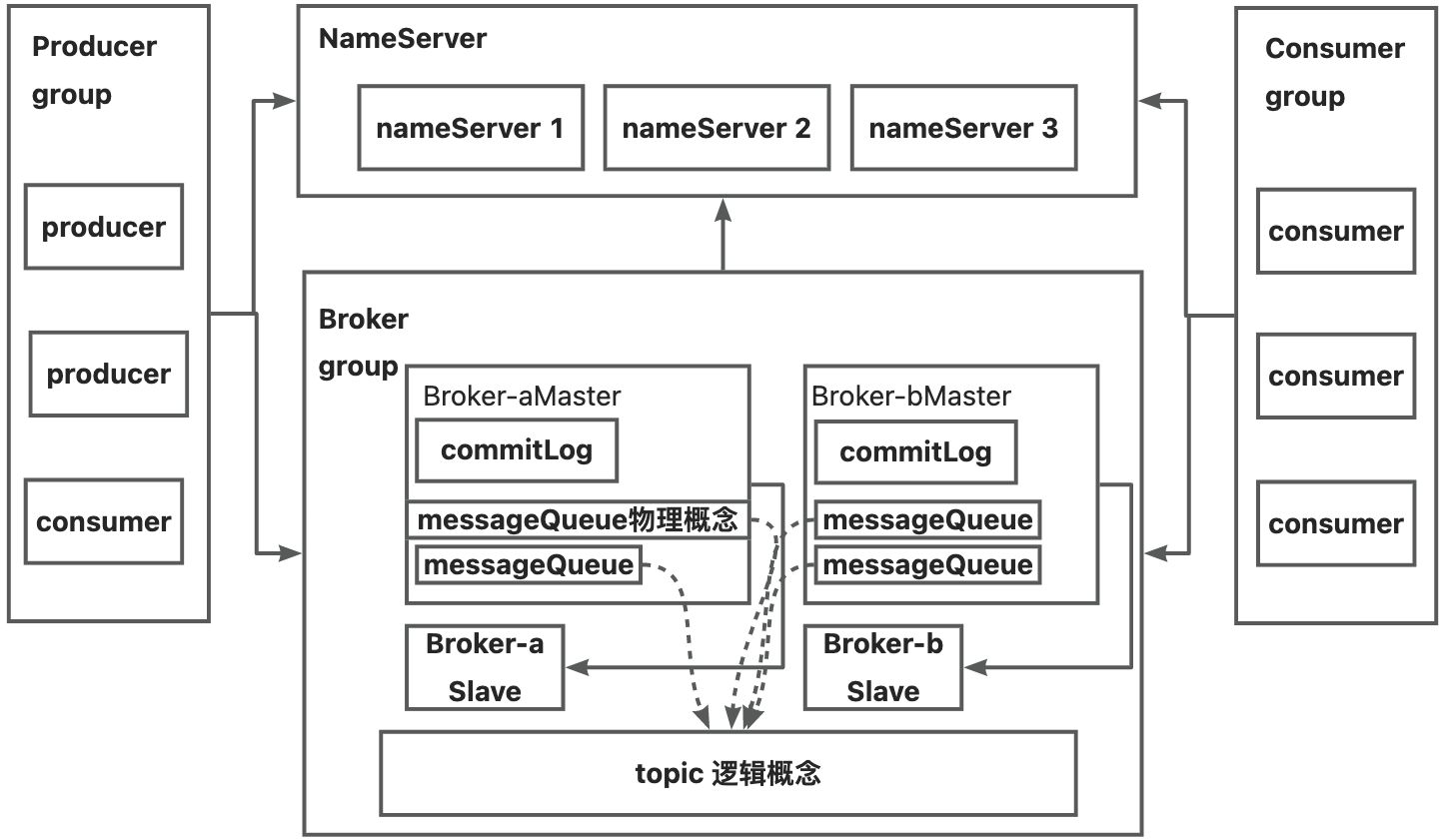
- NameServer 命名服务器 : 提供轻量级的Broker路由服务。broker 启动的时候就会注册,后续使用心跳保持。多个nameServer之间组成集群是相互独立的,完全没有信息的交换。
- BrokerServer 代理服务器:物理概念。实际处理消息存储、转发等服务的核心组件。通常有两种架构模式:
- 普通集群:master 负责读写,slave 负责消息冗余保存,响应部分读请求。消息同步方式分为同步同步和异步同步。不master 挂掉之后需要手动设置新的mater
- Dledger高可用集群:4.5版本引入的,集群会随机选出一个作为master。完成master、slave节点之间的消息同步。master 挂之后会自动选一个新的master
- Message 消息:物理概念。每条消息必须属于一个主题Topic。有唯一的Message ID,且可以携带具有业务标识的Key。系统提供了通过Message ID和Key查询消息的功能。并且Message上有一个为消息设置的标志,Tag标签。
- 需要注意使用的时候不要把自带的 messageId 作为保证消息幂等的工具,最好自己设置业务上的ID,rocket 不保证这个ID在相同消息内容时候的唯一性。
- Topic主题:逻辑概念,不保存实际消息。实际保存的时候会分片,叫做MessageQueue,对应kafka里面的partition,放在不同的broker。一个发送者可以发送消息给一个或者多个Topic;一个消息的接收者可以订阅一个或者多个Topic消息。消费者组的消费者实例必须订阅完全相同的Topic。
简单使用
- 要启动RocketMQ服务,需要先启动NameServer。注意修改JVM 内存大小
- 参数调整、调优。从应用程序的堆内存大小,到后面的OS的参数定制。
- 消费形式:
- 拉取式消费:主动调用 Consumer 的拉消息方法从Broker服务器拉消息。一旦获取了批量消息,应用就会启动消费过程。
- 推动式消费:Broker收到数据后会主动推送给消费端,该消费模式一般实时性较高。使用比较简单,推模式是拉模式封装出来的。具体的实现方式会在下面介绍
- 消息模式:
- 集群消费模式下,相同Consumer Group的每个Consumer实例平均分摊消息。
- 广播消费模式下,相同Consumer Group的每个Consumer实例都接收全量的消息。
- 编程模型:
- 发送者:创建生产者,指定生产者组名;指定nameServer地址;启动生产者;创建消息对象,指定其topic、tag以及消息体;发送消息;关闭生产者。
- 消费者:创建消费者,指定消费者组名;指定nameServer地址;订阅topic和tag,设置回调函数用来处理消息,启动消费者。
- 消息样例
- 基本样例:同步发送、异步发送(要使用countDownLatch保证所有消息回调方法都执行完了再关闭生产者,需要在发的时候指定 callBack 的实现)、单向发送(producer.sendOneWay方式来发送消息,没有返回值没有回调)
- 顺序消息:局部有序,不是全局有序**。需要自己实现一个QueueSelector,会发送到同一个分区 MessageQueue**,消费的时候给consumer注入的 MessageListenerOrderly对象,内部就会通过锁队列的方式保证消息是一个一个队列来取的,取完再取下一个队列的消息。
- 广播消息:在集群状态(MessageModel.CLUSTERING)下,每一条消息只会被同一个消费者组中的一个实例消费到。而广播模式则是把消息发给了所有订阅了对应主题的消费者,而不管消费者是不是同一个消费者组。消费的进度维护在每一个消费者实例中。
- 延迟消息:有不同的延迟级别,到达时间之后会被转移到真正的 topic 对应的队列去消费,否则只是在系统创建的延迟队列里面存放。
- 批量(攒批)消息:多条合并为一条发送(List
msgs 直接发送出去),减少网络IO,提升吞吐量,默认最大1M,最大支持4MB。超过之后会报错发送失败。 - 展批消息:如果超出了4M,需要自己手写 Splitter 切割 List
msgs ,每次next只返回少量subList去发送即可。保证调用send方法的时候入参是小于4M就好。
- 展批消息:如果超出了4M,需要自己手写 Splitter 切割 List
- 过滤消息:consumer在subscribe的时候。除了指定topic,可以使用tag快速过滤消息,
- 还支持SQL表达式的写法(tag之外的过滤条件可以发送时候给Message设置userProperty)
- 事务消息:保证发送者本地事务和发消息两个操作之间的原子性,不保证消费者,消费者是否成功需要在处理完业务逻辑之后再返回成功,并且注意不要处理业务逻辑的时候新建线程。
kafka
简单介绍
分布式、支持分区(partition,也就是rocketMQ中的messageQueue的概念,但是这个partition是真正存放数据的而不是索引数据)、多副本(replica),基于zookeeper实现(新版本打算自己实现raft)的分布式消息系统,可以实时的处理大量数据。用scala语言编写, Linkedin于2010年贡献给了Apache。
基本概念
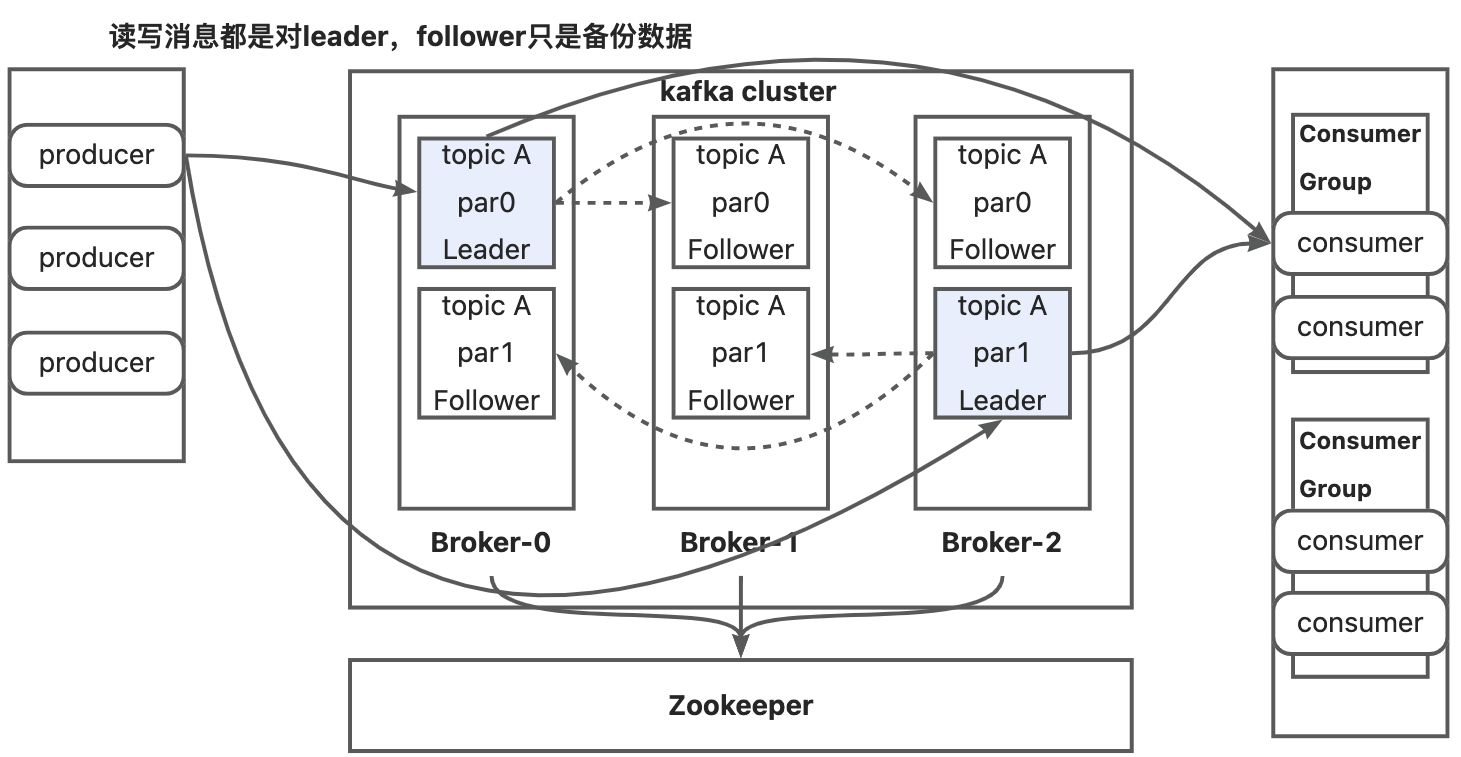
- Broker:一个kafka节点就是一个broker,一个或多个broker组成一个kafka集群。
- Topic:逻辑上,根据 topic 对消息进行归类,发消息的时候是必须指定 topic 的
- Partition:物理上,一个 topic 会被分为多个 partition,每个内部的消息都是有序的。为了应对海量数据场景而设计,同时提高了并行度。
- replica:是分区的备份,也就是 leader 和 follower 是在分区的概念上区分出来的。
- 消息日志 commit Log:每一个partition中的消息都是有唯一的编号 offset 的,同一 partition 的消息的编号一定不同,不同partition 中的消息的offset 可能相同。消息消费之后不会被删除,只会根据日志保留时间
**log.retention.hours**确认多久删除,默认保留最近一周的日志,消息量大小和性能没有关系。但是分区的多少和性能有关系,因为分区越多就会创建越多的commitLog文件,磁盘随机读写消耗较大。
- Consumer:每个consumer是基于自己在commit log中的消费进度(offset)来进行工作的。在kafka中,消费offset由consumer自己来维护;我们可以指定消费的 offset的位置。
- ConsumerGroup:每一个 Consumer都属于一个ConsumerGroup,一条消息可以被多个不同的消费者组消费,但是一个消费者组只能有一个consumer消费该消息,和rocketMQ 一样,消费者组里面消费者的数量不要超出 topic 的分区的数量,否则会有消费者分不到分区。
- 分布式协调器 zookeeper:将很多集群关键信息记录在zookeeper里,保证自己的无状态,从而在水平扩容时非常方便。
简单使用
- 略
Spring Cloud Stream 使用中的一些关键概念
详细参考:https://blog.csdn.net/qq_32734365/article/details/81413218
由于是将MQ的使用抽象了一层统一的编程框架,所以是有助于构建高扩展和事件驱动的微服务系统框架。替换其他MQ方便。
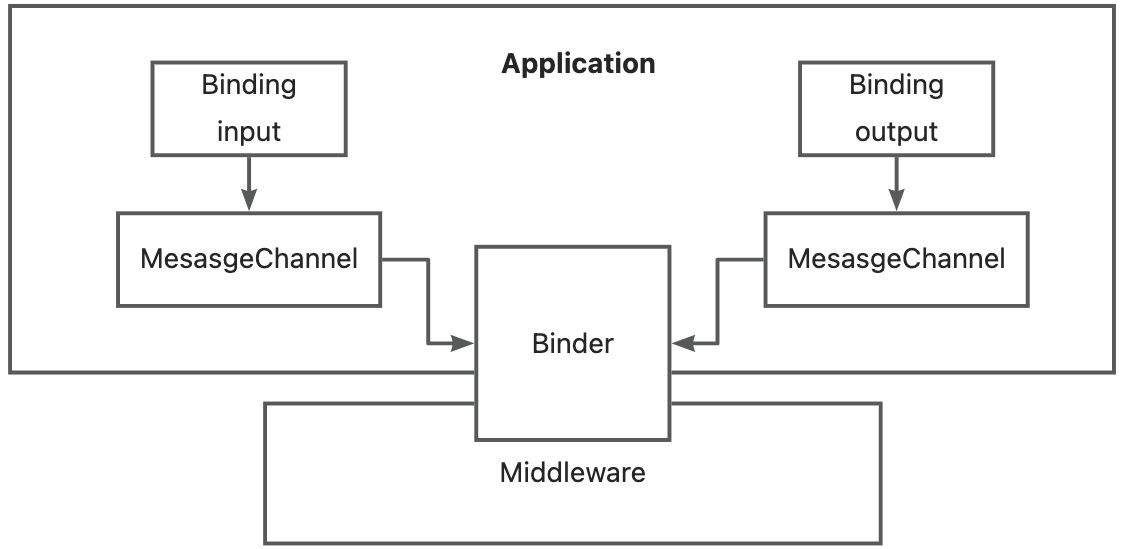
Binder : 外部的消息服务器
- SCStream是通过Binder来定义一个外部消息服务器。为构造Binding提供了 2 个方法,分别是bindConsumer和bindProducer,它们分别用于构造生产者和消费者。目前官方的实现有 Rabbit Binder 和 Kafka Binder, Spring Cloud Alibaba 内部已经实现了 RocketMQ Binder。
- 并且支持配置多个Binder访问不同的外部消息服务器,通过
**spring.cloud.stream.binders.[bindername].environment.[props]=[value]**的格式来进行配置服务器相关的IP端口和账号等信息。另外,如果配置了多个binder,也可以通过**spring.cloud.stream.default-binder**属性指定默认的 binder。 - 对于RabbitMQ来说,Binder就是一个Exchange的抽象。默认情况下,RabbitMQ的binder使用了 SpringBoot的ConnectionFactory,支持spring-boot-starter-amqp 组件中提供的对RabbitMQ的所有配置信息。也就是application.properties里以spring.rabbitmq开头的配置。
1 | spring.cloud.stream.binders.testbinder.environment.spring.rabbitmq.host=localhost |
Binding:消息交互桥梁
- Binding 是连接应用程序跟消息中间件的桥梁,用于消息的消费和生产,由binder创建。通过Binding,即可以声明消息生产者,也可以声明消息消费者。
spring.cloud.stream.bindings.[bindingname].[props]=[value]
1 | spring.cloud.stream.bindings.output.destination=scstreamExchange |
- @EnableBinding()注解接收一个或者多个接口类型的参数。
- 接口的格式,内部有对应的输入和输出方法,方法的返回值是MessageChannel