
ElasticSearch
发表于|更新于|后端
|浏览量:
ElasticSearch的应用场景说明
全文检索能力

日志存储分析能力

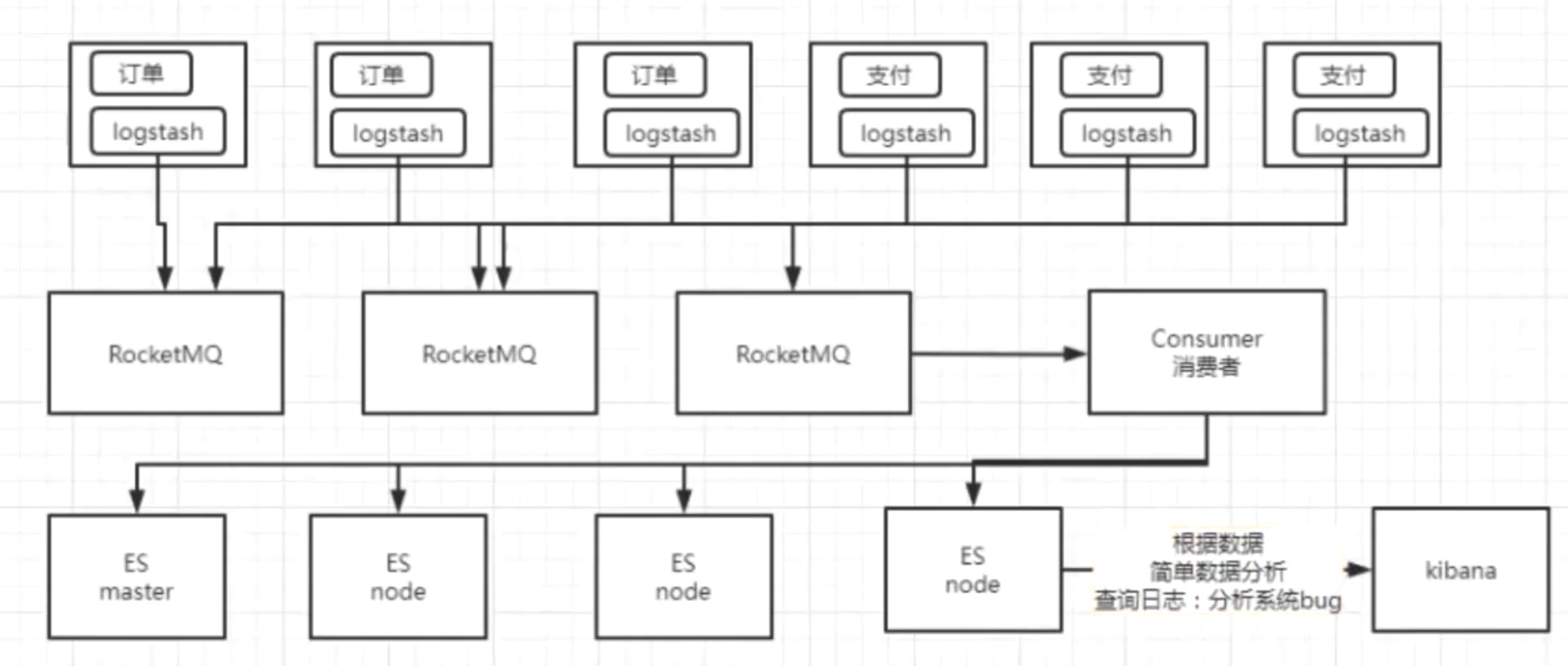

数据存储(用的比较少)

全文检索
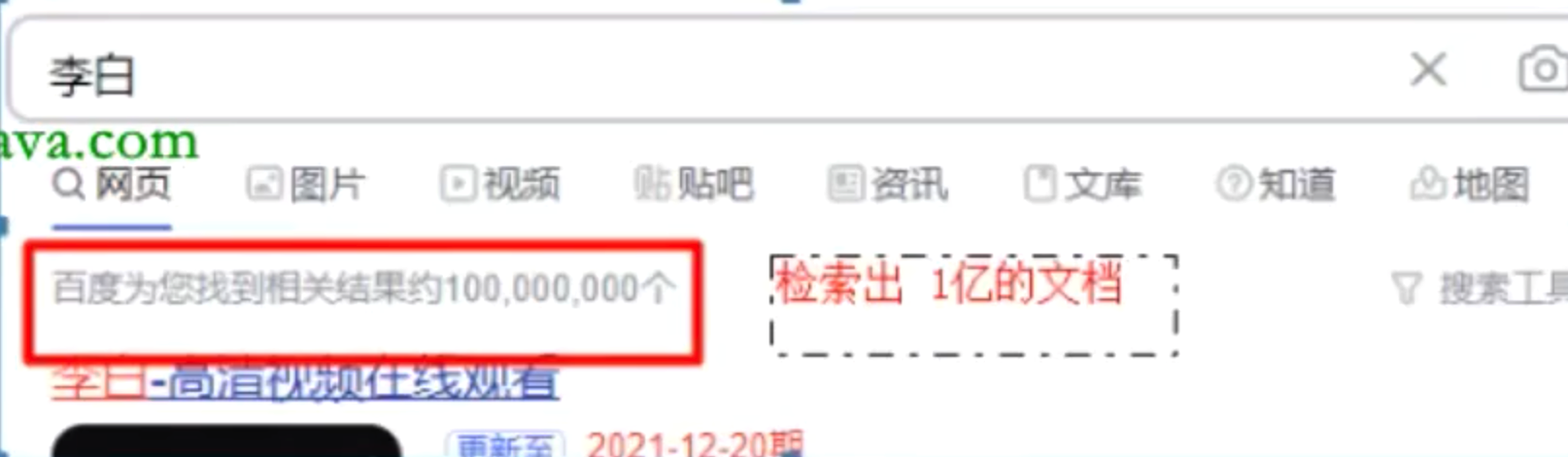
什么是全文检索


存在索引关键字,就是命中文档
使用关键字就可以搜索对应的文档数据
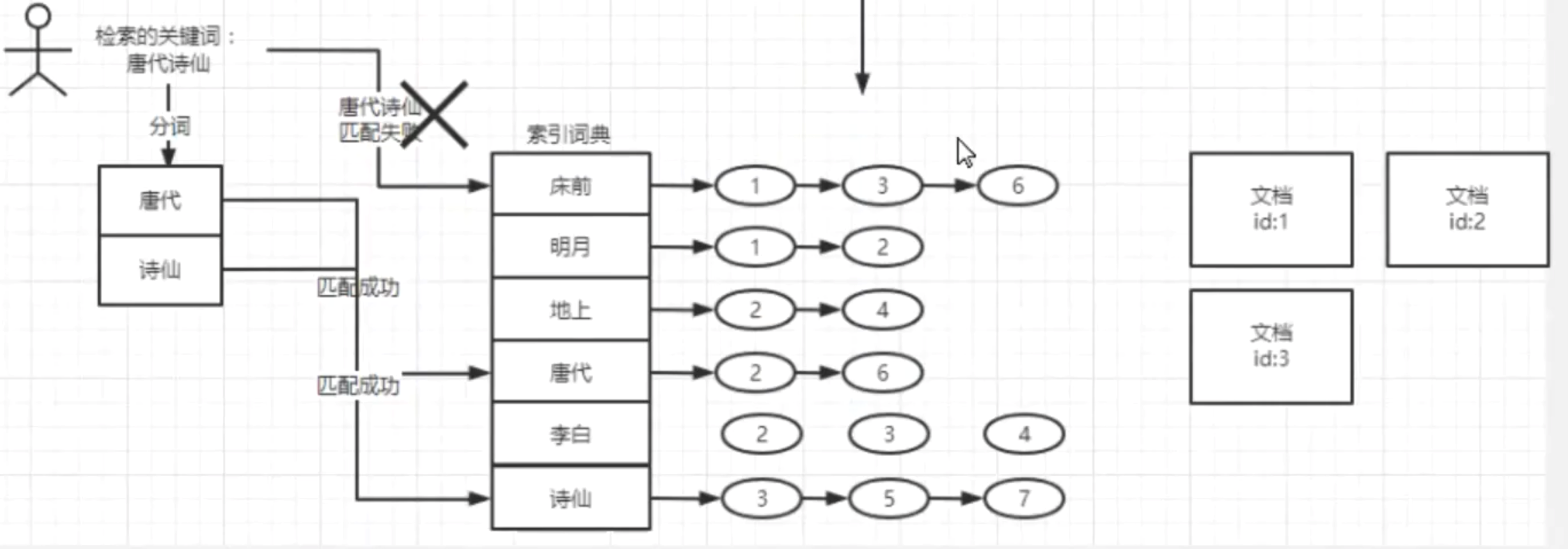
检索算法

倒排索引
先将非结构化数据转换为结构化数据,之后使用关键字建立索引


全文检索的结构
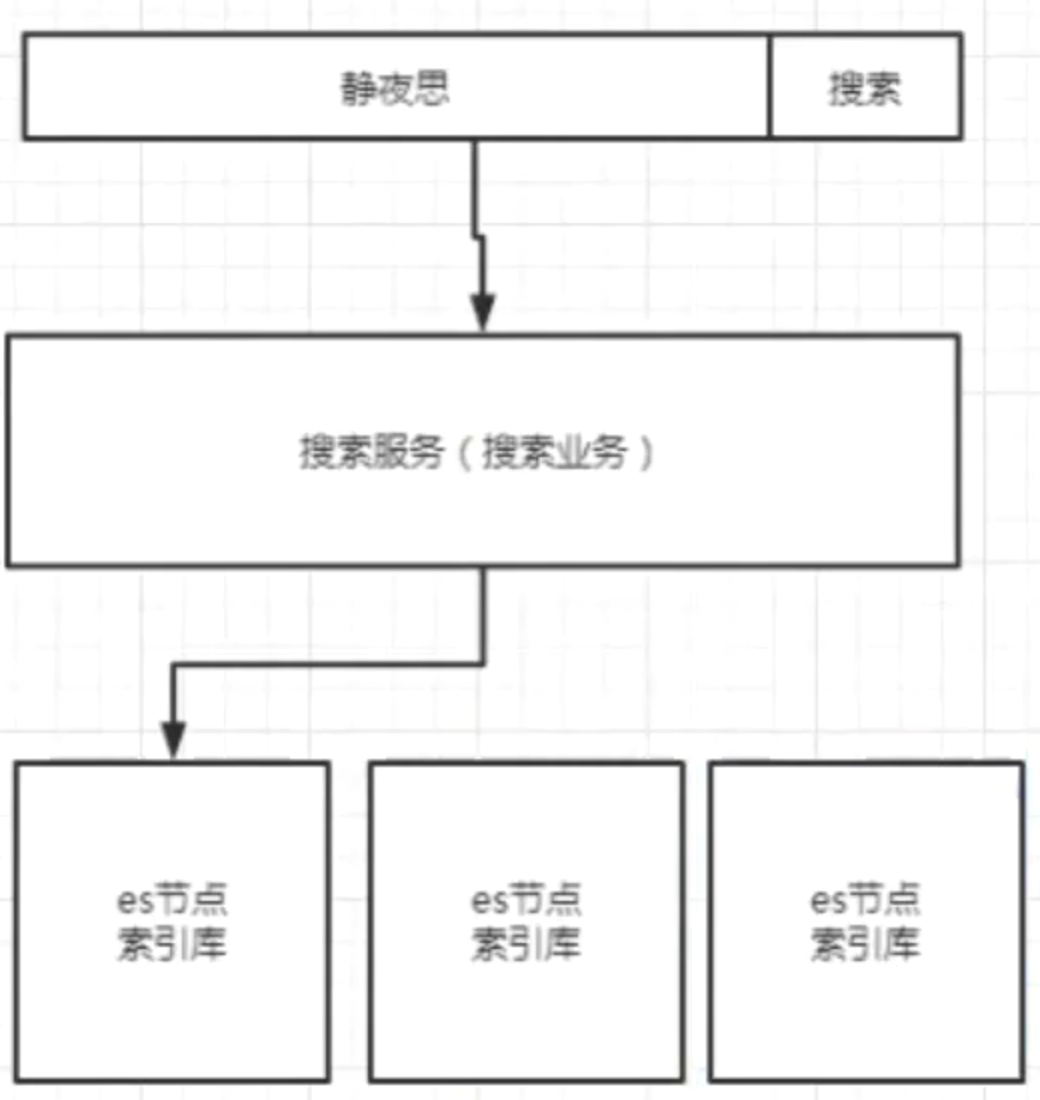

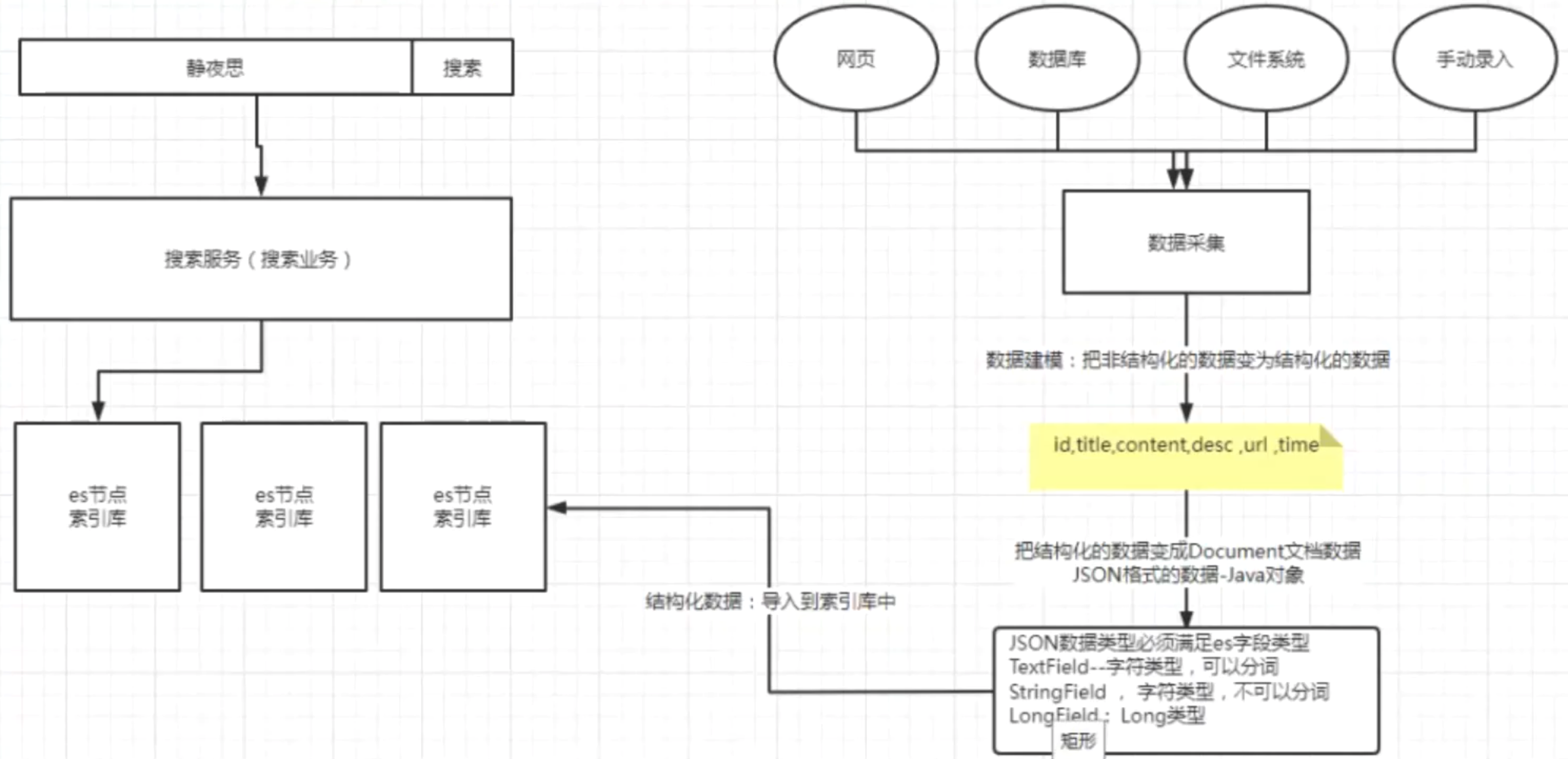
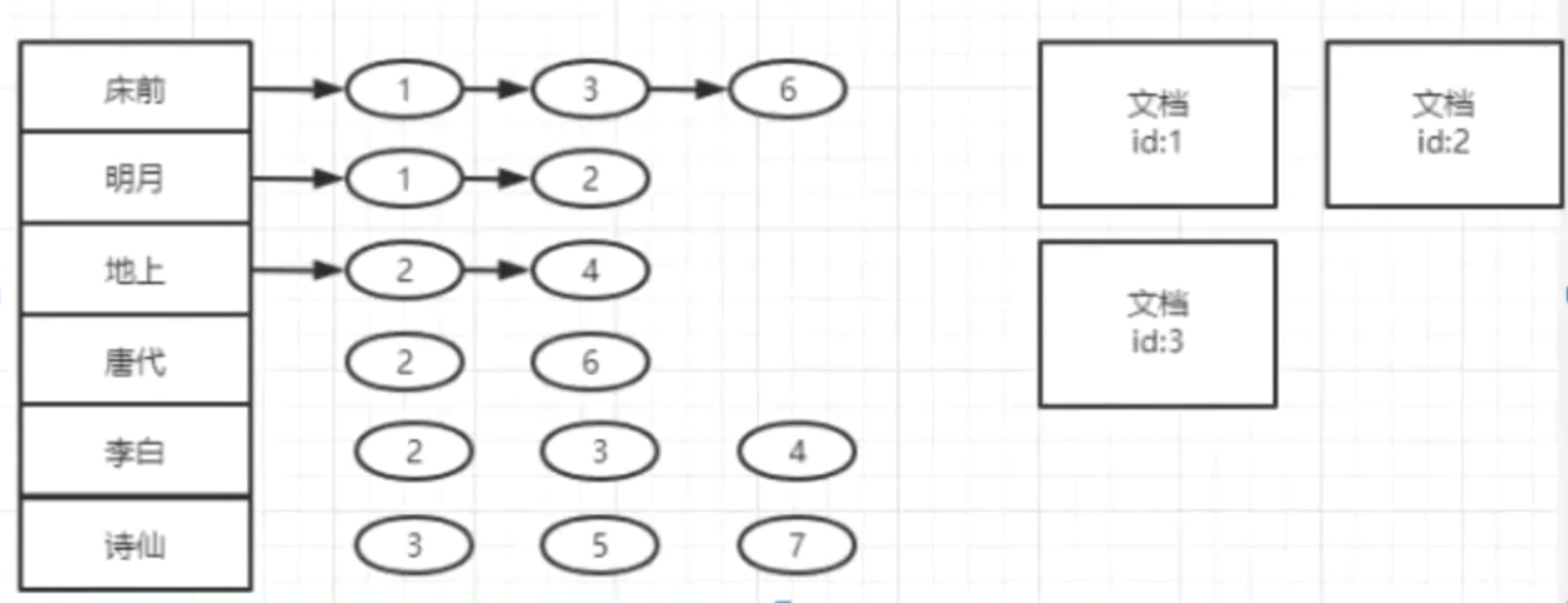
索引库结构
检索流程
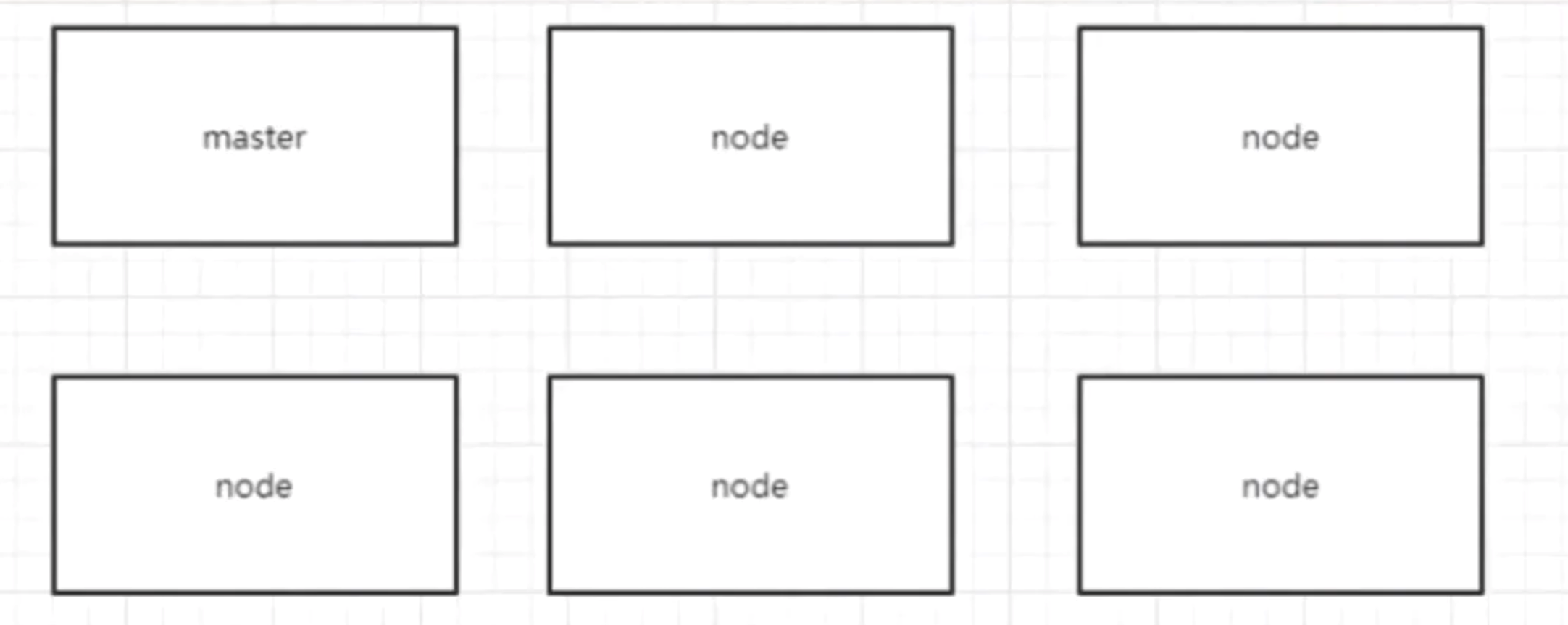
ElasticSearch 实践与集群架构
ES 集群架构




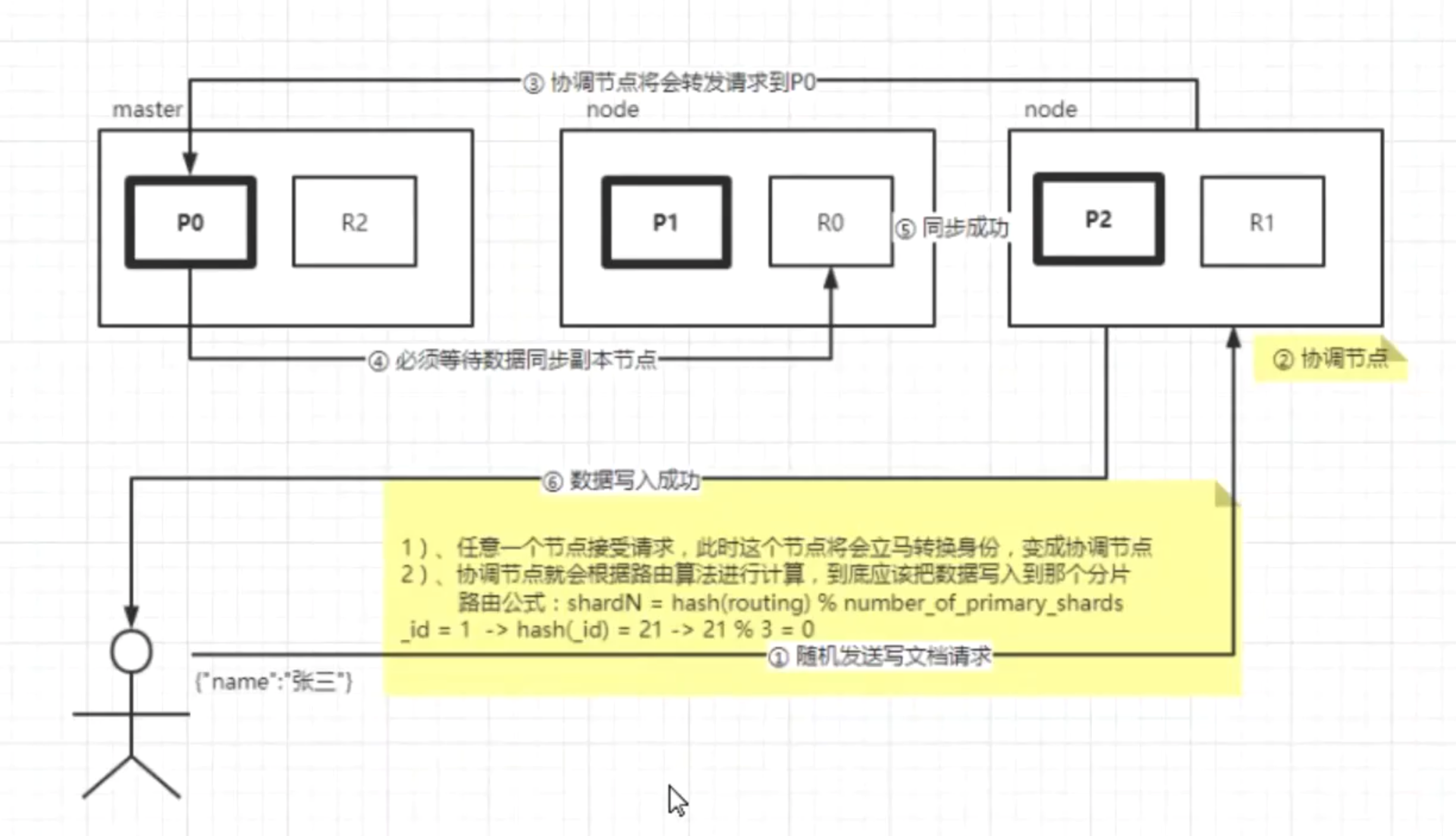
ES是如何进行分片存储的?

主分片和副本分片的关系:
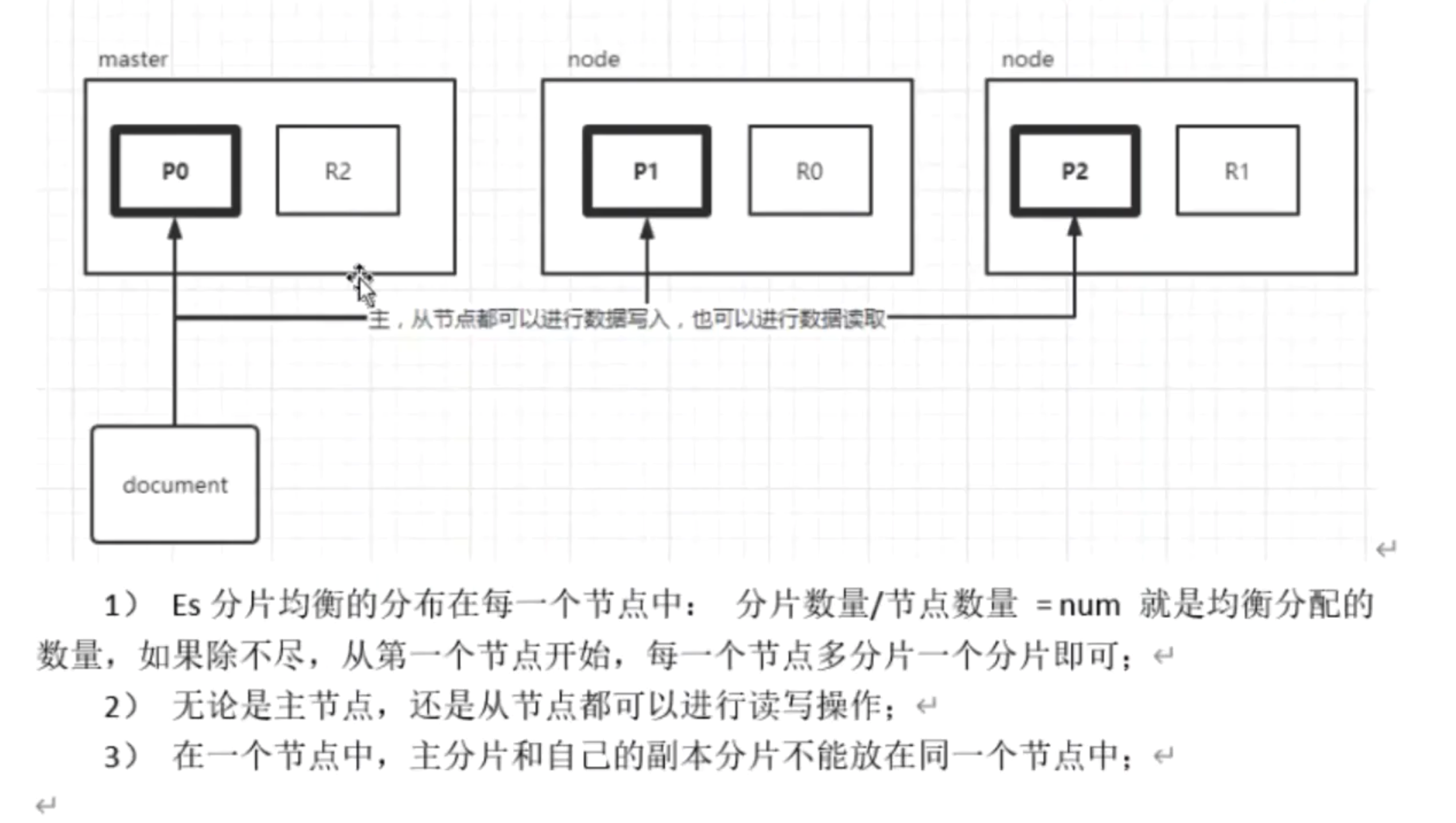

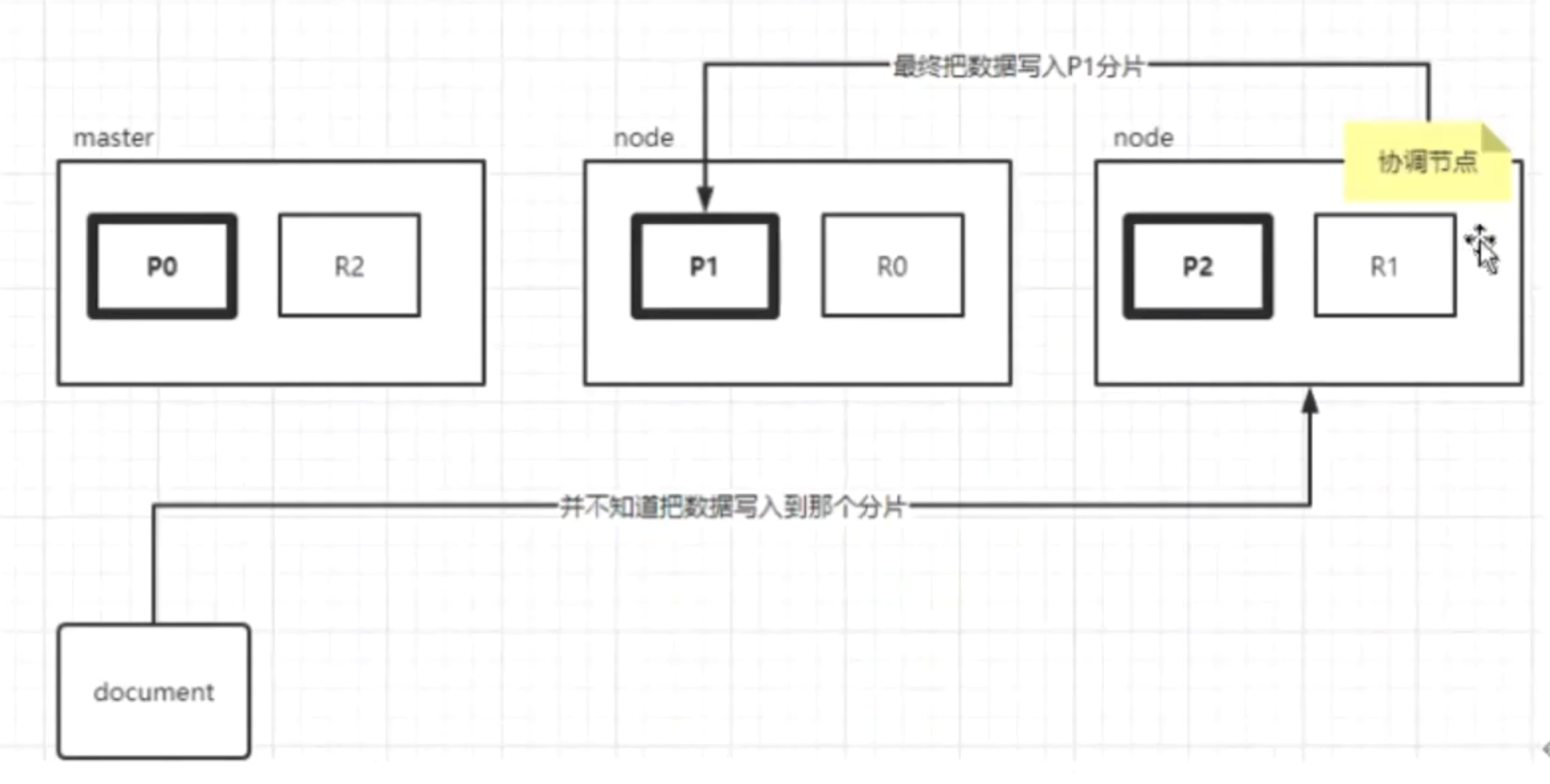
数据在主分片上做写入,主从节点都可以进行数据写入和数据的读取。
主分片是读写,从分片只可以读不可以写。
分片和节点是不一样的。
节点类型




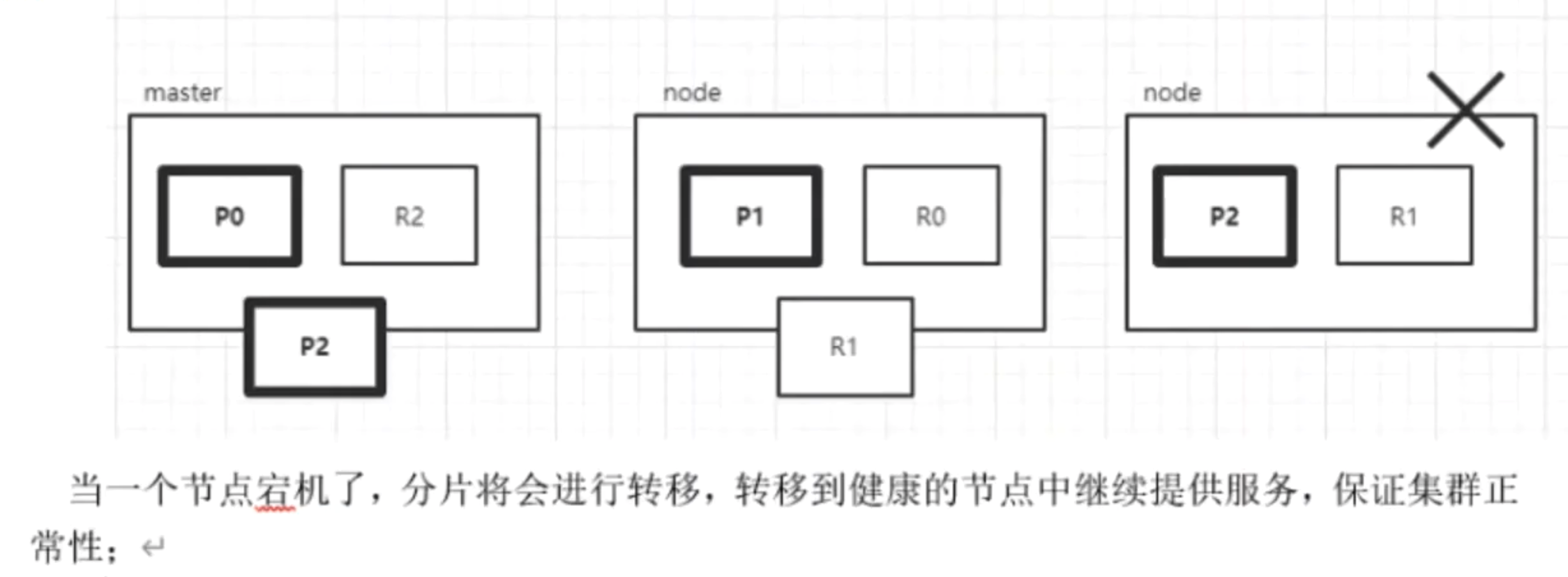
ES集群故障转移
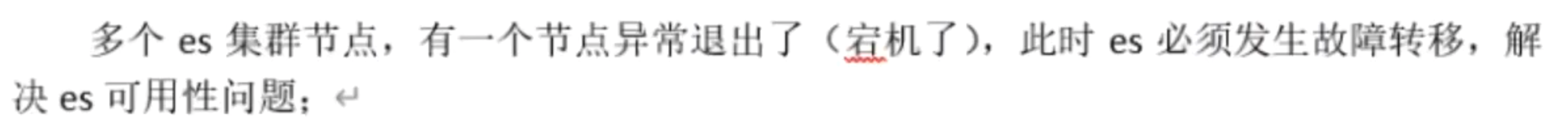

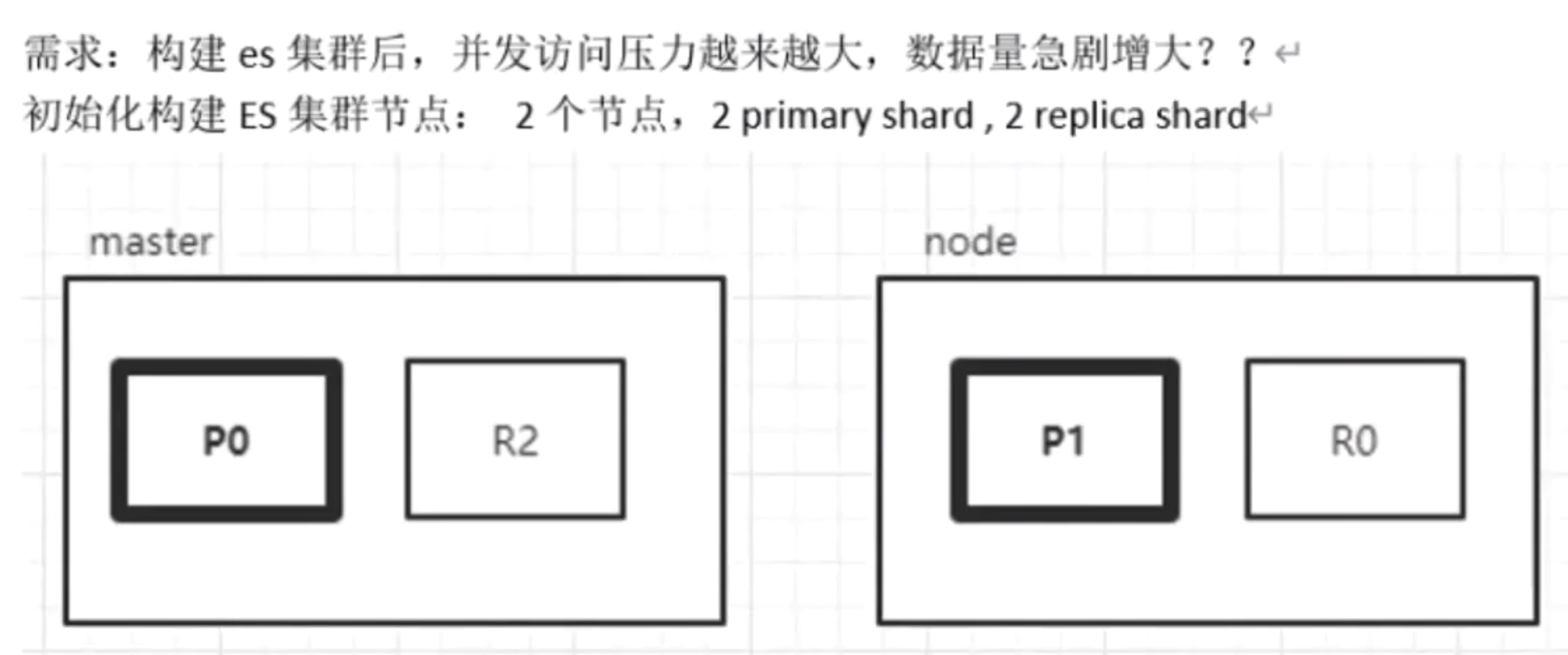
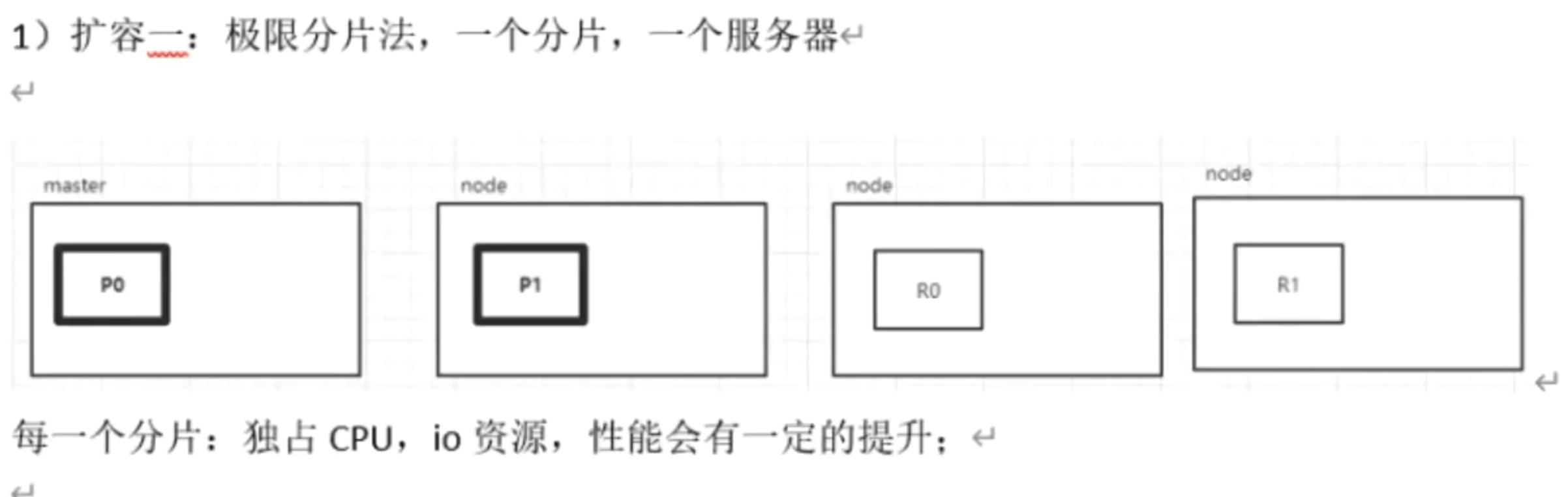
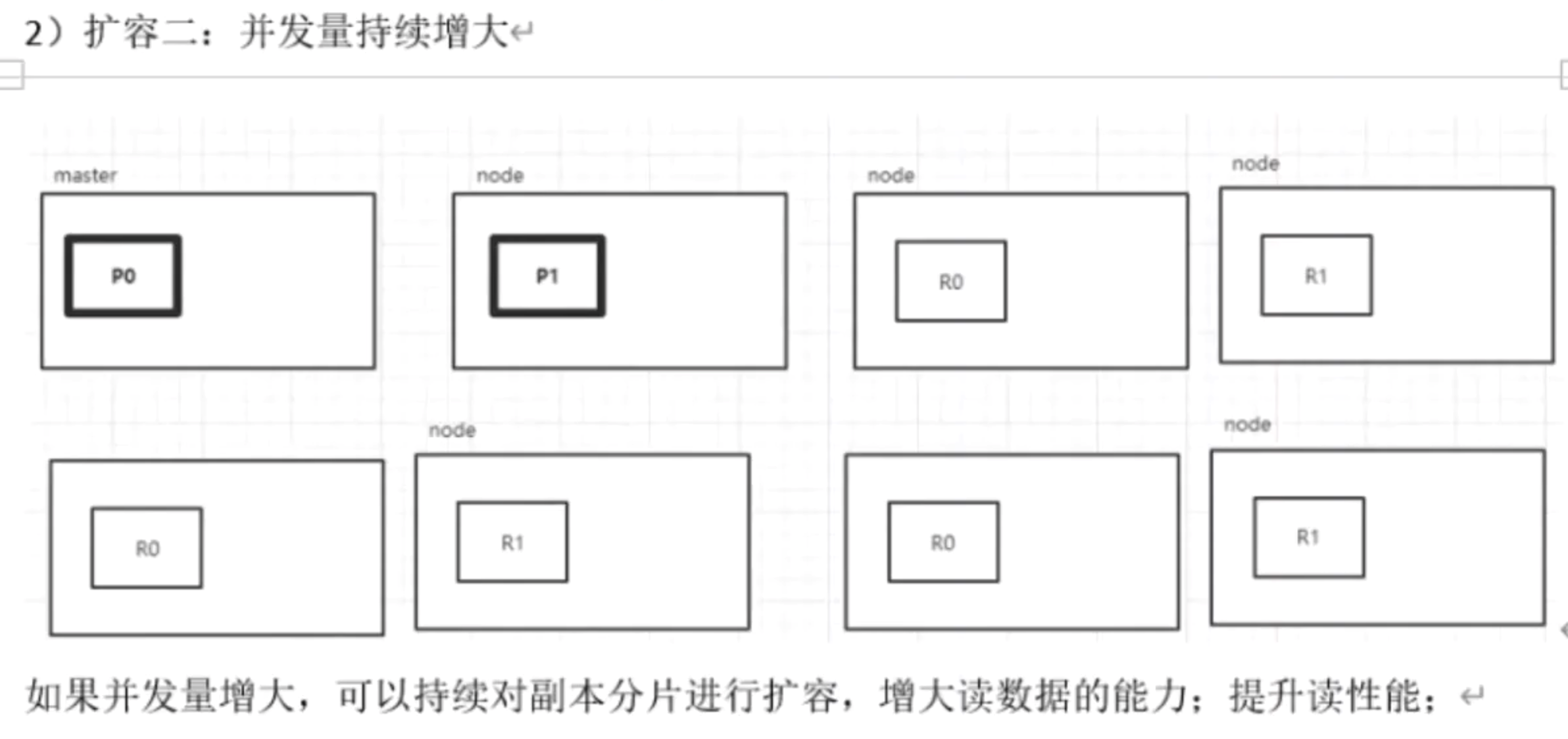
ES横向扩容能力
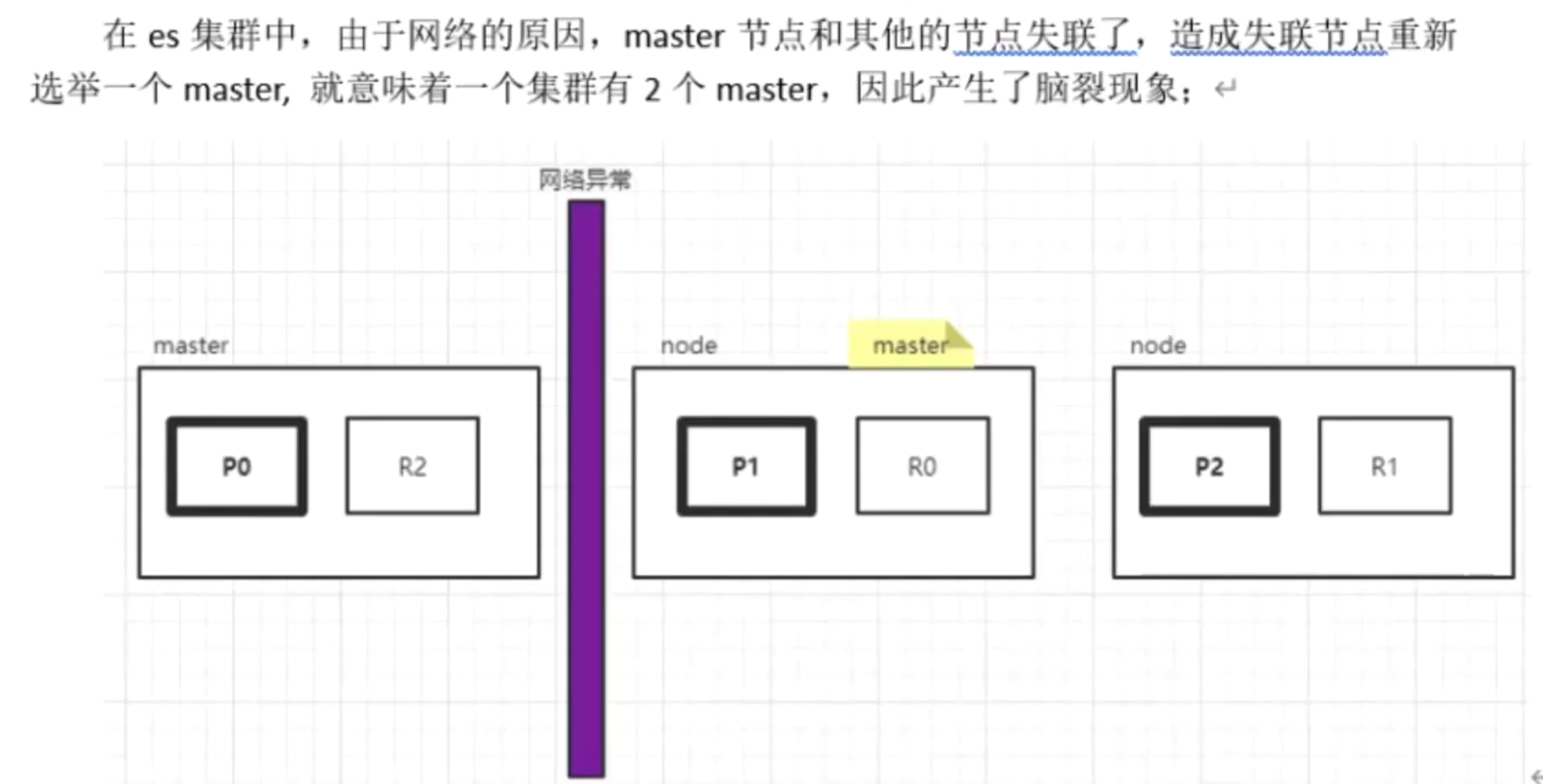
ES 集群脑裂

文档读写路由


文章作者: 褚成志
版权声明: 本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 褚成志的分享站!
相关推荐
2026-04-09
大数据概述
大数据( Big Data):指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。 主要解决海量数据的额存储和分析计算 特点:大量,高速,多样,低价值密度, 应用场景:物流仓储,分析用户零售,智慧旅游,广告推荐,保险预测,人工智能 大数据生态 1)Sqoop:Sqoop是一款开源的工具,主要用于在Hadoop、Hive与传统的数据库(MySql)间进行数据的传递,可以将一个关系型数据库(例如 :MySQL,Oracle 等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。 2)Flume:Flume是一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据; 3)Kafka:Kafka是一种高吞吐量的分布式发布订阅消息系统; 4)Storm:Storm用于“连续计算”,对数据流做连续查询,在计算时就将结果以流的形式输出给用户。 5)Spark:Spark是当前最流...
2026-04-09
Hadoop-MapReduce
dr.who是通过http连接的默认用户,可以直接在配置文件里面修改为当前用户,重启之后就可以使用当前用户在页面里面对文件进行相关操作。 MapReduce概述分布式运算程序的编程框架,是用户开发“基于Hadoop的数据分析应用”的核心框架。 MapReduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个Hadoop集群上。 优点**MapReduce ****易于编程**它简单的实现一些接口,就可以完成一个分布式程序,这个分布式程序可以分布到大量廉价的PC机器上运行。 好的扩展性当你的计算资源不能得到满足的时候,你可以通过简单的增加机器来扩展它的计算能力。 高容错性MapReduce设计的初衷就是使程序能够部署在廉价的PC机器上,这就要求它具有很高的容错性。比如其中一台机器挂了,它可以把上面的计算任务转移到另外一个节点上运行,不至于这个任务运行失败,而且这个过程不需要人工参与,而完全是由Hadoop内部完成的。 适合PB级以上海量数据的离线处理可以实现上千台服务器集群并发工作,提供数据处理能力。 缺点不擅长实时计算MapRedu...
2026-04-09
Hadoop概念以及安装
Hadoop概论 Hadoop是一个由 Apache基金会所开发的分布式系统基础架构。 主要解决,海量数据的存储和海量数据的分析计算问题。 广义上来说, Hadoop通常是指一个更广泛的概念 Hadoop生态圈。 Hadoop三大发行版本:Apache、Cloudera、Hortonworks。 Apache版本最原始(最基础)的版本,对于入门学习最好。 Cloudera内部集成了很多大数据框架。对应产品CDH。用的最多,方便 Hortonworks文档较好。对应产品HDP。 高可靠性: Hadoop底层维护多个数据副本,所以即使 Hadoop某个计算元素或存储出现故障,也不会导致数据的丢失。 2)高扩展性:在集群间分配任务数据,可便的扩展数以千计的节点。 3)高效性:在 MapReduce的思想下, Hadoop是并行工作的,以加快任务处理速度。 4)高容错性:能够自动将失败的任务重新分配 Hadoop组成计算+资源调度+存储 1.x中MapReduce负责计算和资源调度 2.x中MapReduce负责计算,Yarn负责资源调度,解耦 HDFS存储 Hadoop ...
2026-04-09
Hadoop-yarn
Yarn资源调度器Yarn是一个资源调度平台,负责为运算程序提供服务器运算资源,相当于一个分布式的操作系统平台,而MapReduce等运算程序则相当于运行于操作系统之上的应用程序。 Y****arn基本架构YARN主要由ResourceManager、NodeManager、ApplicationMaster和Container等组件构成。 Y****arn工作机制 (1)MR程序提交到客户端所在的节点。 (2)YarnRunner向ResourceManager申请一个Application。 (3)RM将该应用程序的资源路径返回给YarnRunner。 (4)该程序将运行所需资源提交到HDFS上。 (5)程序资源提交完毕后,申请运行mrAppMaster。 (6)RM将用户的请求初始化成一个Task。 (7)其中一个NodeManager领取到Task任务。 (8)该NodeManager创建容器Container,并产生MRAppmaster。 (9)Container从HDFS上拷贝资源到本地。 (10)MRAppmaster向RM 申请运行MapT...
2026-04-09
presto配置
presto启动时默认配置文件目录在安装目录下的etc下 每个节点的配置在etc下创建node.properties文件,配置如下: 123node.environment=productionnode.id=ffffffff-ffff-ffff-ffff-ffffffffffffnode.data-dir=/var/presto/data node.environment: 集群名字,一个集群内所有的节点必须一致。 node.id: 节点id,每个节点同一集群内保持唯一。 node.data-dir:节点数据目录,数据目录用于存放日志和服务的pid。 服务配置presto server分为coordinator和worker,coordinator可以认为是master节点,worker可以认为是计算节点。配置时在etc下创建config.properties文件。 coordinator配置如下:12345678coordinator=truenode-scheduler.include-coordinator=falsehttp-server.http.port=8...
2026-04-09
SpringDataElasticsearch聚合实现过滤搜索
过滤功能分析整个过滤部分有3块: 顶部的导航,已经选择的过滤条件展示: 商品分类面包屑 其它已选择过滤参数 过滤条件展示,又包含3部分 商品分类展示 品牌展示 其它规格参数 展开或收起的过滤条件的按钮 顶部导航要展示的内容跟用户选择的过滤条件有关。这部分需要依赖第二部分:过滤条件的展示和选择。展开或收起的按钮是否显示,取决于过滤条件有多少,如果很少,那么就没必要展示。所以也是跟第二部分的过滤条件有关。 先做第二部分:过滤条件展示。 分类和品牌过滤条件 获取和展示数据库中已经有所有的分类和品牌信息。无论是分类信息,还是品牌信息,都应该从搜索的结果商品中进行聚合得到。 扩展返回的结果返回的结果PageResult对象,里面只有total、totalPage、items3个属性。现在要对商品分类和品牌进行聚合,添加分类和品牌的数据。 分类:页面显示了分类名称,但背后肯定要保存id信息。所以至少要有id和name 品牌:页面展示的有logo,有文字,当然肯定有id,基本上是品牌的完整数据 新建一个类,继承PageResult,然后扩展两个新的属性:分类集合和品牌集合: 123...
公告
👋 你好,我是褚成志,一名专注于云原生与后端架构的工程师。
热爱 Java、Kubernetes、Linux、Redis、Spring 等技术领域,持续探索 AGI 与智能化运维的边界。
这里记录我的技术思考与实践总结,欢迎交流!
热爱 Java、Kubernetes、Linux、Redis、Spring 等技术领域,持续探索 AGI 与智能化运维的边界。
这里记录我的技术思考与实践总结,欢迎交流!
目录